
SEO
更新日: 2024/11/22
【イラスト付き】クローラーとは?検索順位が決まるまでの流れも解説!

ねえねえブルーちゃん?
?


クライアントから「Googleにインデックスされるまでの流れを教えて欲しい」って言われたんだけど、その流れを教えてくれないかしら??
あぁ、それはクローラーの話をする必要があるねー

それじゃあ今回は、クローラーとは何かを紹介するね


クローラーとは?


クローラーとは、検索エンジンが検索結果を表示するために、Webサイトの情報を収集する巡回ロボット(Bot)のことだよ

Googleなどの検索エンジンは、世の中にたくさんあるWebサイトを巡回するのに、クローラーを使ってWebサイトの情報を集めてるんだよねー
その情報を読み込んだ上で、適切なキーワードに表示したり、順位を付けたりしているのね!


そうそう!だからGoogleに表示してもらうには、まずはクローラーにクローリングしてもらわないといけないんだよ

クローラーが拾える情報は?

クローラーが拾える情報は、
◆ HTML
◆ CSS
◆ Javascript
◆ 画像データ
◆ PDFファイル
などを拾うことができるよ!
だから、クローラーはWebサイトに表示されているデータは、ほとんど余すところなく取得するようにできてるんだよねー
検索エンジンはそれだけ、ユーザーのニーズに当てはまる精密な検索結果を提示しようとしてるのね!


クローラーの巡回から順位が決まるまでの流れを解説!
次は、クローラーの巡回手順から、検索結果の順位が決まるまでの一連の流れを紹介するね
順位が決まるまでの流れ1.クローラーがrobots.txtにアクセス

まず最初に、クローラーは「robots.txt」にアクセスするんだ
「robots.txt」っていうのは、どのページにアクセスしてはいけないかを教えるためのファイルだよ
世の中のクローラーは、まず「robots.txt」を見て、アクセスしてはいけないページを把握するんだよねー

robots.txtを置く場所は、例えば「example.com/robots.txt」っていうURLに置く必要があるのに注意しないといけないよ
順位が決まるまでの流れ2.アクセスしてはいけないページ以外にアクセス

次に、クローラーは「robots.txt」でアクセスを禁止されているページ以外に、アクセスを始めるよ
この時、「ページ内にあるリンク」や「sitemap.xml」を辿ってページを見つけるんだよねー

ページを見つけてもらうために、ページにリンクはしっかりと置かないとダメなんだよ
順位が決まるまでの流れ3.検索エンジンにインデックスする

次は、クローラーが持ってきた情報を、検索エンジンにインデックスするんだよ
インデックスっていうのは、検索エンジンのデータベースに、クローラーが持ってきたデータを保存することだねー
クロールはされても、インデックスされないと検索結果に表示されないから、重要な工程だよ!
順位が決まるまでの流れ4.ユーザー行動により、検索結果での順位を変え続ける

最後に検索エンジンは、検索結果でのユーザー行動も加味して、検索結果での順位を変え続けるんだよ
検索結果での動きも反映されるの?!

うん、そうだよ
例えば、
1. 1位のページをユーザーがクリック
2. サイトから戻ってきて、2位のページをユーザーがクリック
3. そのまま戻ってこなかった
っていう行動をするユーザーが多いなら、1位のページよりも、2位のページの方が、ユーザーが求めている情報だよね?
そういう場合は、検索エンジンは2位と1位の順位を入れ替えて、ページを表示するようになるんだよ
こういうふうに検索エンジンは、常にユーザーが最も求めている情報を出そうと頑張ってるんだよねー
クローラーはユーザーのような動きはできない
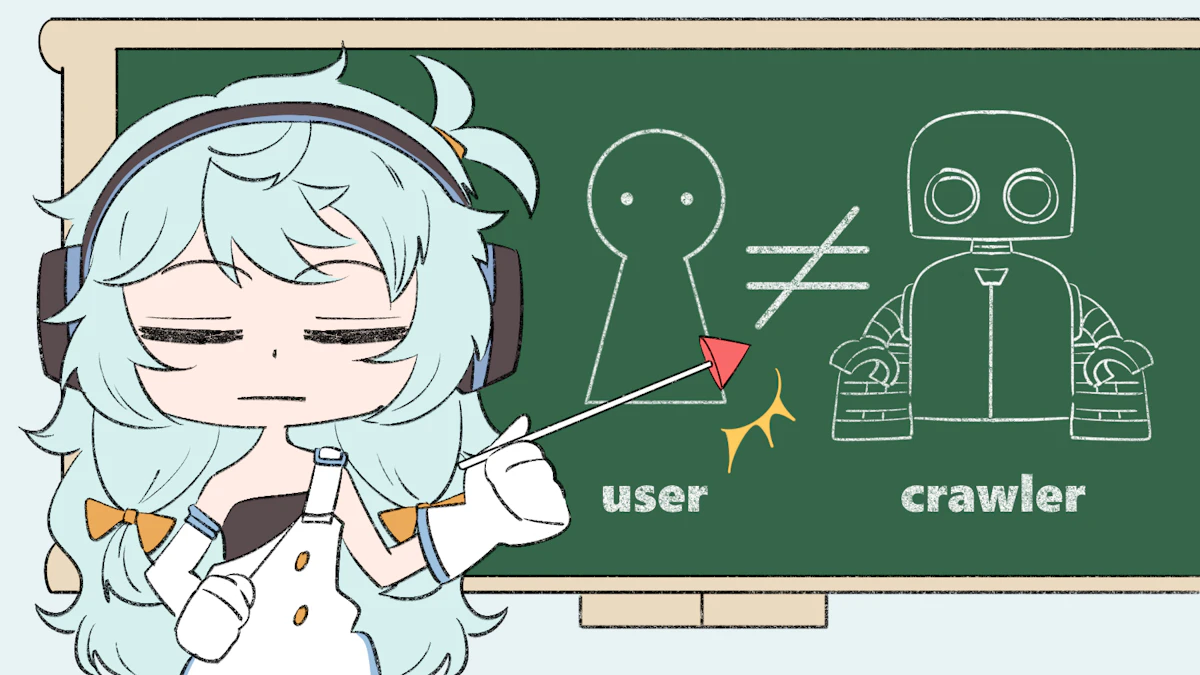
実は、クローラーはユーザーのような動きはしないんだよ
もっと具体的には「ユーザー行動で生成されるコンテンツ」を取得することはしないよ

例えば、クローラーはリンクを追って他のページを探すけど、aタグのhref内にあるリンクを辿ることはしても、「クリックすることでJavascriptでURLを生成する仕様のリンク」を取得することはしないんだ
他にも、無限スクロールっていうスクロールで生成されるコンテンツとかも認識できないねー
だから、もしもサイト内のリンクを全てbuttonタグにしている場合は、クローラーがページを巡回しやすいようにaタグに置き換えてあげる必要があるよ
まとめ
クローラーについてまとめると、、、
まとめ
◆クローラーとは、検索エンジンが検索結果を表示するために、Webサイトの情報を収集する巡回ロボット(Bot)のこと
◆クローラーは「HTML」「CSS」「Javascript」「画像データ」「PDFファイル」などを拾える
◆クローラーは「robots.txt」でアクセスしてはいけないページを把握してから、それ以外のページをリンクを辿って、Webサイトの情報を集める
◆クローラーが集めた情報をもとにインデックス処理が行われ、ユーザー行動に基づいて検索結果での順位が決まる
こんな感じだねー
さすがブルーちゃん!わかりやすかったわ!
クライアントに説明してくるね!
いってらっしゃーい



最新の記事一覧

日本語ドメインとは?初めに知っておきたいメリット・デメリット
SEO

ルートドメインとは?迷いやすいサブドメインとの違いも確認
SEO

ページエクスペリエンスとは?仕組みと種類を整理
SEO

コンテンツのインタラクションとは?伸びない原因と対策を整理!
SEO

SEOのトレーニング方法は?独学でも習得できるコツを解説
SEO

離脱率の放置はSEOに悪影響!まず見直したい基本ポイント
SEO

サイト最適化は何から始めたらいい?押さえるべきポイント
SEO

SEOメディアはどう運用する?初心者でも失敗しないためのコツ
SEO

アダルトSEOが苦戦する理由は?簡単にできる施策も解説!
SEO

自然検索で見つけてもらう方法は?流入を増やすためのポイント
SEO

SEOのチェックツールはどれが便利?おすすめ5選を紹介
SEO

SEO対策を東京で依頼するならどこ?都内でおすすめの会社5選
SEO

noindexとは?検索結果に出さない設定を分かりやすく解説
SEO

レスポンスの意味は?今さら聞けない基礎を分かりやすく解説
SEO

トレンドとは?理解するポイントとマーケティングでの活用方法
SEO

SEOダッシュボードのメリットを解説!作成のステップも
SEO

ローカル検索とは?ランキング決定方法や対策ポイントを解説
SEO

BtoC企業必見!SEOでブランドを強くする方法を解説!
SEO

BtoBにおけるSEOの重要性とは?成果を出すための実践法を解説
SEO

リッチスニペットとSEOの関係・表示方法を徹底解説!
SEO

最新の記事一覧

日本語ドメインとは?初めに知っておきたいメリット・デメリット
SEO

ルートドメインとは?迷いやすいサブドメインとの違いも確認
SEO

ページエクスペリエンスとは?仕組みと種類を整理
SEO

コンテンツのインタラクションとは?伸びない原因と対策を整理!
SEO

SEOのトレーニング方法は?独学でも習得できるコツを解説
SEO

離脱率の放置はSEOに悪影響!まず見直したい基本ポイント
SEO

サイト最適化は何から始めたらいい?押さえるべきポイント
SEO

SEOメディアはどう運用する?初心者でも失敗しないためのコツ
SEO

アダルトSEOが苦戦する理由は?簡単にできる施策も解説!
SEO

自然検索で見つけてもらう方法は?流入を増やすためのポイント
SEO

SEOのチェックツールはどれが便利?おすすめ5選を紹介
SEO

SEO対策を東京で依頼するならどこ?都内でおすすめの会社5選
SEO

noindexとは?検索結果に出さない設定を分かりやすく解説
SEO

レスポンスの意味は?今さら聞けない基礎を分かりやすく解説
SEO

トレンドとは?理解するポイントとマーケティングでの活用方法
SEO

SEOダッシュボードのメリットを解説!作成のステップも
SEO

ローカル検索とは?ランキング決定方法や対策ポイントを解説
SEO

BtoC企業必見!SEOでブランドを強くする方法を解説!
SEO

BtoBにおけるSEOの重要性とは?成果を出すための実践法を解説
SEO

リッチスニペットとSEOの関係・表示方法を徹底解説!
SEO
